")
كيف تستنسخ صوتك بالذكاء الاصطناعي في 2026 (خطوة بخطوة + أفضل الأدوات)
تعلم كيف تستنسخ صوتك بالذكاء الاصطناعي في حوالي 30 ثانية. دليل خطوة بخطوة لاستنساخ الصوت، والحصول على أفضل جودة، وإضافة المشاعر، والاستنساخ بلغات أخرى — مع الجانب الأخلاقي.
تخيّل أن تسجّل مقطعاً مدته 30 ثانية مرة واحدة، ثم لا تجلس أمام ميكروفون أبداً بعد ذلك.
هذا ما يفعله استنساخ الصوت. تُعطي الذكاء الاصطناعي عينة قصيرة من صوتك، فيتعلم أن ينطق أي نص تكتبه — بصوتك، وبنبرتك، ولهجتك، وإيقاعك.
لصانعي المحتوى، يعني هذا سرداً متسقاً عبر كل فيديو. للشركات، يعني توسيع الإنتاج الصوتي دون إعادة تسجيل. ولأي شخص، يعني صوتاً شخصياً يمكن إعادة استخدامه في أي مكان.
في هذا الدليل، ستتعلم كيف تستنسخ صوتك بالذكاء الاصطناعي خطوة بخطوة، وكيف تحصل على نسخة تبدو مثلك فعلاً، وكيف تضيف المشاعر، وكيف تفعل كل ذلك بمسؤولية.
لنبدأ.
الإجابة السريعة: لاستنساخ صوتك بالذكاء الاصطناعي، سجّل حوالي 30 ثانية من الصوت النظيف، وارفعها إلى أداة استنساخ الصوت، وانتظر لحظة بينما يبني الذكاء الاصطناعي نموذج صوتك. بعد ذلك، اكتب أي نص فينطقه بصوتك المستنسَخ — ويمكنك ضبط المشاعر بل واستخدامه بلغات أخرى.
ما هو استنساخ الصوت بالذكاء الاصطناعي؟
استنساخ الصوت بالذكاء الاصطناعي هو تقنية تنشئ نسخة رقمية من صوت محدد انطلاقاً من عينة صوتية قصيرة. وبمجرد وجود النسخة، يمكنك كتابة أي نص وسماعه منطوقاً بذلك الصوت — حتى الكلمات التي لم يسجّلها المتحدث الأصلي قط.
إليك ما يحدث خلف الكواليس، بعبارات بسيطة:
- تقدّم عينة مرجعية — حوالي 30 ثانية من الكلام المسجَّل.
- يحلّل الذكاء الاصطناعي صوتك — طبقة الصوت، النبرة، الإيقاع، اللهجة، والتفاصيل الصغيرة التي تجعلك تبدو أنت.
- يبني نموذجاً صوتياً — نسخة رقمية قابلة لإعادة الاستخدام من صوتك.
- تولّد كلاماً جديداً — اكتب أي نص، فيقرؤه النموذج بصوتك.
الهدف كله هو إعادة الاستخدام. استنسخ مرة واحدة، ثم ولّد صوتاً غير محدود دون أن تسجّل مجدداً أبداً.
ماذا يمكنك أن تفعل بصوت مستنسَخ
الصوت المستنسَخ ليس مجرد طرفة — إنه أداة إنتاج. وبمجرد امتلاكه، يندمج في كل ما تنشئه.
- سرد فيديو متسق — الصوت نفسه عبر كل فيديو على يوتيوب، ولو بفارق أشهر.
- تعليقات صوتية بالحجم — ولّد عشرات المقاطع دون إعادة تسجيل واحدة.
- استضافة البودكاست — استخدم صوتك المستنسَخ كمضيف في بودكاست بالذكاء الاصطناعي بدلاً من تسجيل كل حلقة.
- الكتب الصوتية والمحتوى الطويل — اسرد فصلاً كاملاً بالكتابة، لا بالقراءة بصوت عالٍ لساعات.
- نسخة متعددة اللغات منك — تحدّث لغات لا تتقنها فعلاً (المزيد عن ذلك أدناه).
الميزة الحقيقية أن نسخة واحدة تعمل في كل مكان. على AnySpeech، الصوت الذي تنشئه يمكن استخدامه عبر تحويل النص إلى كلام والبودكاست وأكثر — استنسخه مرة، واستخدمه في كل أداة.
كيف تستنسخ صوتك بالذكاء الاصطناعي — خطوة بخطوة
استنساخ صوتك يستغرق بضع دقائق فقط، ومعظمها يذهب للتسجيل. إليك العملية الكاملة.
الخطوة 1: سجّل عينة مرجعية نظيفة
سجّل حوالي 30 ثانية وأنت تتحدث بشكل طبيعي. اقرأ فقرة تشعر بالراحة معها، بنبرتك العادية — ليس أداءً، بل أنت تتحدث فحسب.
الجودة هنا أهم من الطول. مقطع نظيف مدته 30 ثانية يتفوق على مقطع مزعج مدته دقيقتان في كل مرة.
الخطوة 2: ارفع عينتك
افتح أداة استنساخ الصوت وارفع تسجيلك. يمكنك أيضاً التسجيل مباشرة إذا كان محيطك هادئاً.
الخطوة 3: دع الذكاء الاصطناعي يبني نموذج صوتك
يعالج الذكاء الاصطناعي عينتك ويبني نموذج صوتك. يستغرق هذا لحظة — لا عليك سوى الانتظار.
الخطوة 4: اكتب نصك وولّد
بمجرد جاهزية نسختك، اكتب أي نص تريده أن يقوله. انقر على توليد، فيقرأ النموذج نصك بصوتك المستنسَخ.
الخطوة 5: اضبط، ثم حمّل
عاين المخرجات. اضبط الصياغة أو المشاعر أو الإيقاع إن لزم، ثم حمّل الصوت واستخدمه حيث تشاء.
نصيحة احترافية: اختبر نسختك الجديدة بجملة سبق أن قلتها بصوت عالٍ فعلاً. إنها أسرع طريقة للحكم على مدى تطابق النسخة — أذنك تعرف صوتك أنت أفضل من أي أحد.
كيف تحصل على نسخة بأفضل جودة
جودة نسختك تتحدد بالكامل تقريباً بعينتك المرجعية. اضبط العينة، فيتحسّن كل ما يأتي بعدها.

افعل هذا لعينة نظيفة:
- سجّل في غرفة هادئة. لا تلفاز، لا ضجيج مرور، لا موسيقى خلفية.
- ابقَ قريباً من الميكروفون. حتى سماعات الهاتف تعمل جيداً إذا كانت الغرفة هادئة.
- تحدّث بشكل طبيعي. استخدم نبرتك وإيقاعك اليومي، لا صوت مذيع إذاعي.
- متحدث واحد فقط. لا أصوات متداخلة ولا ثرثرة خلفية.
- نوّع جملك. بضع جمل مختلفة تلتقط من مداك أكثر من سطر واحد مكرّر.
تجنّب هذه القواتل الشائعة للجودة:
- الغرف ذات الصدى (الحمامات، القاعات الفارغة)
- الموسيقى أو الطنين الخلفي
- التمتمة أو الكلام السريع جداً
- التشويه الناتج عن الصوت العالي جداً
اضبط هذه الأمور، وستبدو نسختك أقرب إليك بشكل ملحوظ.
إضافة المشاعر إلى صوتك المستنسَخ
من أكثر الشكاوى شيوعاً عن الأصوات المستنسَخة أنها تبدو مسطحة — دقيقة تقنياً، لكنها خالية من الحياة عاطفياً. الحل هو التحكم بالمشاعر.
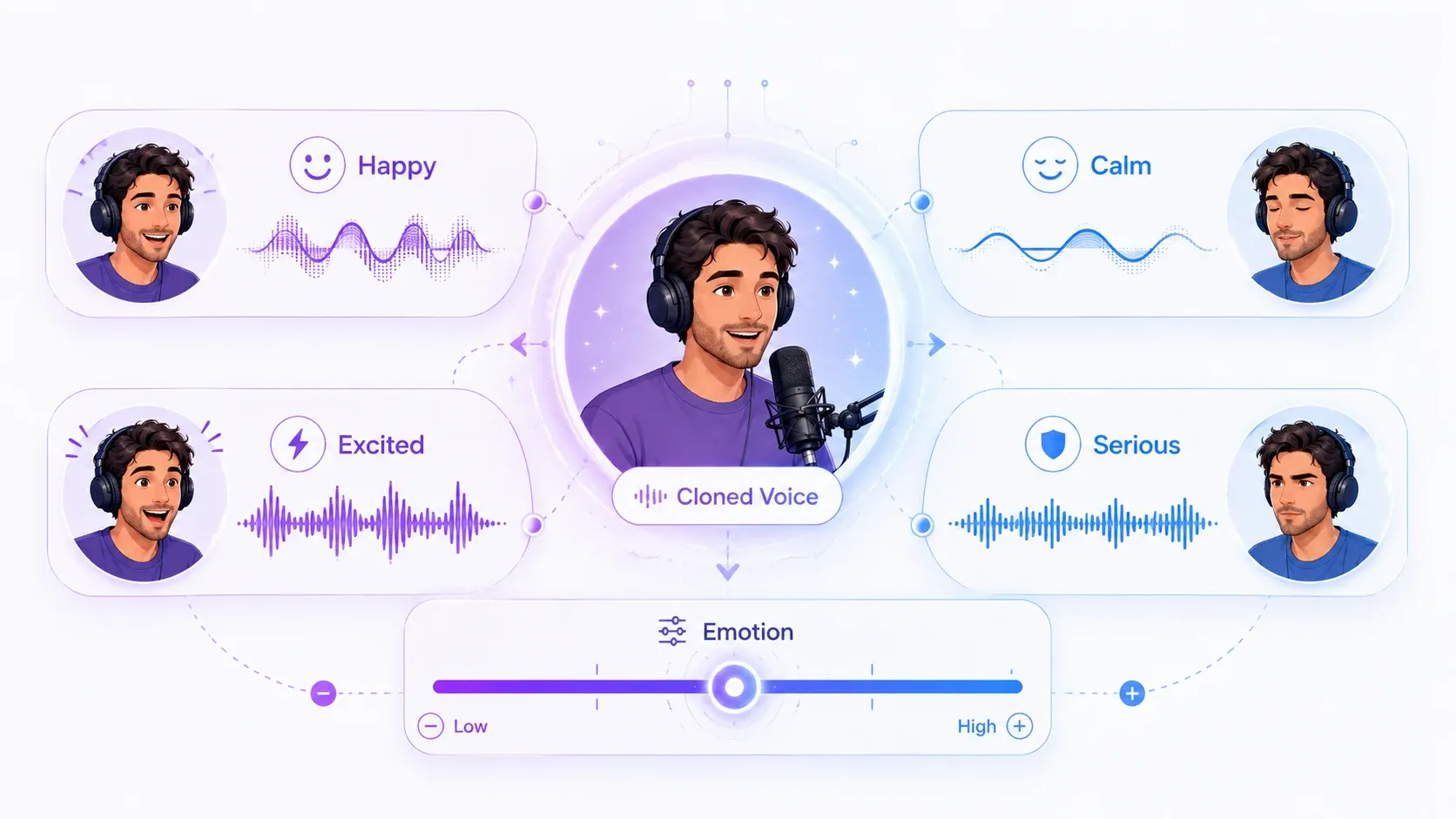
مع استنساخ الصوت من AnySpeech، يمكنك توجيه طريقة إلقاء كل سطر — سعيد، هادئ، متحمس، جاد — بدلاً من نبرة واحدة ثابتة لكل شيء. الجملة نفسها يمكن أن تأتي كتشجيع مرح أو كشرح متّزن، حسب ما يحتاجه محتواك.
هذه هي التفصيلة التي تتجاهلها معظم الأدوات، وهي ما يفصل بين نسخة تبدو كتسجيل ونسخة تبدو كآلة:
- استخدم إلقاءً مفعماً بالحيوية للمحتوى التسويقي ومحتوى التواصل الاجتماعي.
- استخدم إلقاءً هادئاً للدروس أو التأمل أو الشروحات.
- استخدم إلقاءً متحمساً للمقدمات الترويجية والإعلانات ولحظات الحماس.
مطابقة المشاعر مع المحتوى هي أكبر تحسين منفرد يمكنك إدخاله على صوت مستنسَخ.
استنساخ صوتك بلغات أخرى
هنا يصبح استنساخ الصوت مذهلاً حقاً: يمكنك التحدّث بلغات لم تتعلّمها أبداً.
لأن الذكاء الاصطناعي يلتقط طابع صوتك بدلاً من كلمات بعينها، يمكنه تطبيق صوتك على لغات أخرى. تسجّل مرة واحدة بالإنجليزية، فتستطيع نسختك التحدّث بالإسبانية والفرنسية واليابانية وعشرات غيرها — وتظل تبدو مثلك.
تدعم AnySpeech الأصوات المستنسَخة عبر أكثر من 40 لغة. لصانعي المحتوى ذوي الجماهير الدولية، يعني هذا أن جلسة تسجيل واحدة تنتج سرداً لكل سوق تخدمه — دون توظيف ممثل صوتي لكل لغة.
| حالة الاستخدام | بدون استنساخ | مع نسخة متعددة اللغات |
|---|---|---|
| الوصول إلى 5 أسواق | 5 ممثلين صوتيين | تسجيل واحد، 5 لغات |
| اتساق العلامة التجارية | صوت مختلف لكل منطقة | الصوت نفسه في كل مكان |
| مدة الإنجاز | أيام إلى أسابيع | دقائق |
أفضل أدوات استنساخ الصوت بالذكاء الاصطناعي في 2026
عدة أدوات تقدّم استنساخ الصوت، لكنها تتفاوت في كمية الصوت التي تحتاجها، وما إذا كانت تدعم المشاعر، وعدد اللغات التي تغطيها. إليك مقارنة صادقة.
| الأداة | العينة المطلوبة | التحكم بالمشاعر | اللغات | الأفضل لـ |
|---|---|---|---|---|
| AnySpeech | ~30 ثانية | نعم | 40+ | الاستنساخ والمشاعر في مكان واحد |
| ElevenLabs | دقيقة+ | محدود | 30+ | الإنتاج الإنجليزي بكثافة |
| Resemble AI | ~10 ثوانٍ | نعم | متعددة | المطورون وواجهات البرمجة |
| Descript (Overdub) | ~10 دقائق | لا | إنجليزي بالأساس | التحرير داخل Descript |
أهم الميزات هي التحكم بالمشاعر وتغطية اللغات — فهما ما يقرّر إن كانت نسختك صالحة لمحتوى حقيقي أم مجرد عرض تقني. لجولة أوسع على أدوات الصوت، اطّلع على دليلنا حول أفضل أدوات تحويل النص إلى كلام، أو قارن أفضل بدائل Play.ht إذا كانت أسعار الاستنساخ ودعم اللغات هي معياري الاختيار لديك.
هل استنساخ الصوت قانوني؟ الأخلاق والسلامة
استنساخ الصوت قانوني حين تستنسخ صوتك أنت أو حين تملك إذناً صريحاً من صاحب الصوت الذي تستنسخه. استنساخ صوت شخص دون موافقته هو حيث يتجاوز الأمر الحد — قانونياً وأخلاقياً.

بعض القواعد الأساسية لتبقى على الجانب الصحيح:
- استنسخ صوتك أنت فقط — أو احصل على موافقة واضحة. استنساخ شخصية عامة أو زميل أو أي شخص آخر دون إذن قد ينتهك قوانين الخصوصية وانتحال الشخصية، إضافةً إلى شروط معظم المنصات.
- كن شفافاً. إذا نشرت صوتاً مولّداً بالذكاء الاصطناعي لشخص حقيقي، فصرّح بذلك. الخداع هو ما يوقع الناس في المشاكل، لا التقنية نفسها.
- احمِ نفسك من عمليات احتيال الصوت. استُخدم استنساخ الصوت في عمليات احتيال هاتفية تقلّد أفراد العائلة أو المدراء. اتفق على "كلمة سر" شفهية مع المقرّبين، وتحقّق من الطلبات العاجلة غير المتوقعة عبر قناة ثانية.
- أبقِ الحقوق التجارية واضحة. الأدوات الموثوقة تتيح لك استخدام صوتك أنت المستنسَخ تجارياً. تسمح AnySpeech بالاستخدام التجاري للأصوات التي تنشئها ضمن خططها المدفوعة.
عند استخدامه بمسؤولية، استنساخ الصوت أداة إبداعية قوية. التقنية ليست هي الخطر — استخدامها دون موافقة هو الخطر.
الأسئلة الشائعة
كم من الصوت أحتاج لاستنساخ صوت؟
حوالي 30 ثانية من كلام نظيف وواضح يكفي لنسخة بجودة عالية. الصوت الأكثر قد يساعد، لكن عينة قصيرة عالية الجودة تتفوق على عينة طويلة مزعجة.
كم يستغرق استنساخ الصوت؟
بضع دقائق فقط. بعد رفع عينتك، يبني الذكاء الاصطناعي نموذج صوتك في لحظات، ويمكنك البدء بتوليد الكلام فوراً.
هل استنساخ الصوت مجاني؟
استنساخ الصوت ميزة متميزة مُدرجة ضمن خطط AnySpeech المدفوعة. يمكنك تجربة تحويل النص إلى كلام المجاني في المنصة أولاً لسماع جودة الصوت قبل الترقية.
هل تبدو النسخة مثلي فعلاً؟
نعم. استنساخ الصوت الحديث دقيق للغاية ويلتقط طبقة صوتك ونبرتك ولهجتك. كلما كانت عينتك المرجعية أقرب لطريقة كلامك المعتادة، كانت النتيجة أكثر إقناعاً.
هل يمكنني استخدام صوت مستنسَخ تجارياً؟
نعم — للأصوات التي تملكها. يمكنك استخدام صوتك المستنسَخ ليوتيوب والبودكاست والإعلانات ومشاريع تجارية أخرى ضمن خطة مدفوعة. أما استنساخ صوت شخص آخر للاستخدام التجاري فيتطلب إذنه.
هل يمكنني استنساخ صوت شخص آخر؟
فقط بموافقته الصريحة. استنساخ صوت شخص آخر دون إذن قد يخالف قوانين انتحال الشخصية والخصوصية، وينتهك شروط الخدمة في معظم المنصات.
كيف أجعل الصوت المستنسَخ يبدو أكثر طبيعية؟
ابدأ بعينة مرجعية نظيفة، واكتب بأسلوب حواري، وأبقِ الجمل قصيرة، واستخدم التحكم بالمشاعر لمطابقة الإلقاء مع محتواك. المعاينة والضبط قبل النشر يُحدثان فرقاً كبيراً.
بأي لغات يمكنني استنساخ صوتي؟
تدعم AnySpeech الأصوات المستنسَخة بأكثر من 40 لغة. تسجّل مرة واحدة وتستطيع توليد كلام بلغات عديدة، كلها بصوتك أنت.
استنسخ صوتك وضعه في العمل
استنساخ الصوت يحوّل تسجيلاً واحداً مدته 30 ثانية إلى صوت تستخدمه إلى الأبد — عبر الفيديوهات والبودكاست والكتب الصوتية وأكثر من 40 لغة، مع المشاعر التي تجعله يبدو بشرياً.
المفتاح هو عينة نظيفة، والمشاعر المناسبة لمحتواك، واستخدامه بمسؤولية — صوتك أنت، أو بموافقة واضحة.
جاهز لتسمع نفسك؟
- استنسخ صوتك — أنشئ نموذج صوتك في حوالي 30 ثانية
- استخدمه في بودكاست بالذكاء الاصطناعي — قدّم برنامجاً بصوتك أنت
- تصفّح أكثر من 200 صوت ذكي — إن كنت تفضّل البدء بصوت جاهز
جديد على الأصوات الذكية عموماً؟ ابدأ بدليلنا حول كيفية استخدام تحويل النص إلى كلام بالذكاء الاصطناعي. أسئلة لم نغطّها؟ راسلنا على support@anyspeech.io وسنضيفها إلى الدليل.
الكاتب

التصنيفات
مقالات أخرى
")
كيفية تفعيل عزل الصوت: دليل خطوة بخطوة لكل جهاز (2026)
تعلم كيفية تفعيل عزل الصوت على iPhone وiPad وMac وAndroid. تعليمات خطوة بخطوة لـ FaceTime والمكالمات الهاتفية، ونصائح لأدوات عزل الصوت بالذكاء الاصطناعي.
")
كيفية استخدام تحويل النص إلى كلام بالذكاء الاصطناعي: دليل شامل للمبتدئين (2025)
تعلم كيفية استخدام أدوات تحويل النص إلى كلام بالذكاء الاصطناعي خطوة بخطوة. اكتشف الخيارات المجانية، قارن جودة الأصوات، واحصل على نصائح عملية لإنشاء تعليقات صوتية طبيعية.
")
تحويل النص إلى كلام لأجل إمكانية الوصول: دليل لعسر القراءة وفرط الحركة وضعف البصر (2026)
كيف يساعد تحويل النص إلى كلام في عسر القراءة وفرط الحركة وضعف البصر — من يستفيد، وماذا تقول الأبحاث، وما الذي تبحث عنه في الأداة، وكيف تبدأ القراءة بالأذن مجانًا.